이 게시글을 쓴 이유는 하나다.
강의가 한번 끊기면 공부할 마음도 같이 끊기기 때문에 공부에 집중하기 위해서.
특정 사이트에서 강의를 보고 있었는데 아는 내용도 어느정도 있어 빠르게 넘기려고 했다.
하지만 네트워크의 문제인지 2배속으로 재생하거나 10초 뒤로 몇번 넘기면 자주 끊겼다.
차라리 전체파일을 다운 받아서 보는게 낫다고 생각했고, 공유할 목적이 아닌 혼자만 볼 생각이니 파일을 합쳐도 되지 않을까 해서 바로 실행에 옮겼다.
사용환경
python 3.7.9
첫번째로 파일을 다운로드 할수 있는지 부터 알아보았다.
내가 사용하는 사이트에선 강의를 파일을 일정 시간으로 나눠서 보낸다. (대부분 스트리밍이 그럴것이라고 생각한다)
이 모든 파일을 합치면 전체 비디오를 만들수 있으므로 다운로드 할수 있는지도 알아봐야한다.
개발자 도구의 네트워크 탭에서 xhr 유형을 찾아보면 다음과 같은 파일을 볼수 있다.

내가보는 강의자료는 이렇게 쉽게 찾을수 있지만 다른 이름으로 되어있는 경우는 그 옆 waterfall(폭포)에서 꾸준히 들어오는 데이터를 확인하면 된다.
그다음 링크 주소를 확인하고 새로운 브라우저 창에 넣어보면 다운로드를 할수 있는지 알수있다.
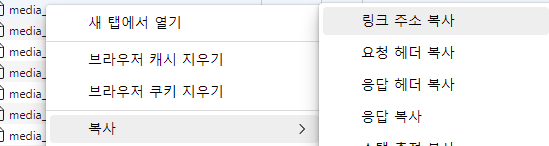
나는 ~~.ts라는 파일로 다운을 받을수 있었다.
두번째는 파이썬에서 다운로드를 하는 코드를 짰다.
urllib.request.urlretrieve를 사용하면 다운로드할수 있다.
import urllib.request
save_name = 'test.ts'
video_url = 'https://url~' # 위에서 복사한 링크 주소를 붙여넣자
urllib.request.urlretrieve(video_url, save_name)위와 같이 작성하고 저장할 이름과 다운로드할 주소를 넣고 실행시키면 test.ts 라는 파일로 저장이 되는걸 확인할수 있다.
세번째는 한 동영상에서 나온 여러 스트림을 한번에 저장했다.
개발자도구의 network탭에서 스트리밍 되는 영상의 파일 이름을 볼수있다.
내가 보는 강의의 영상들은 같은 주소에 맨 뒷자리 숫자만 바뀌는 형태여서 쉽게 작성할수 있었다. (url/file_name_{number}.ts)
import urllib.request
def save_video_stream(video_url, num_of_videos):
try:
for num in range(num_of_videos + 1):
save_name = f'{str(num).zfill(3)}.ts'
real_video_url = f'{video_url}{str(num)}.ts'
urllib.request.urlretrieve(real_video_url, save_name)
except:
print('No File Error or The End')
print("Download complete.")여기에서 try except를 사용한 이유는 num_of_videos에 큰 값을 넣어서 다운로드할게 없으면 끝나게 하기 위해서이다.
네번째는 파일 저장되는 곳을 지정했다.
위 방식으로 하면 python 코드가 있는 위치에 수십, 수백개의 영상을 저장하게 된다.
여러 파일을 저장하게 되면 합칠때 섞일 우려가 있어서 폴더를 생성하고 그 위치에 저장하는 방식으로 만들었다.
import urllib.request
import re
import os
def save_video_stream(video_url, num_of_videos):
# mkdir
dir_name = None
p = re.compile('.mp4$')
for s in video_url.split('/'):
m = p.search(s)
if m:
dir_name = s[:m.span()[0]]
if os.path.exists(dir_name):
pass
elif dir_name:
os.mkdir(dir_name)
else:
dir_name = 'temp'
os.mkdir('temp')
# download videos
try:
for num in range(num_of_videos + 1):
save_name = os.path.join(dir_name, f'{num}.ts')
real_video_url = f'{video_url}{str(num).zfill(3)}.ts'
urllib.request.urlretrieve(real_video_url, save_name)
except:
print('No File Error or The End')
print("Download complete.")regex를 사용해서 마지막에 `.mp4`로 끝나는 것을 폴더 이름으로 지정했다.
그리고 폴더를 만들고, os.path.join을 통해서 파일이 저장되는 위치를 지정했다.
다섯번째는 다운로드된 파일들을 한번에 합치는 과정이다.
파이썬 내장 라이브러리 shutil(shutil.copyfileobj)를 사용하면 파일을 쉽게 합칠수 있다
import shutil
import os
def merge_videos(dir_name):
video_list = sorted(os.listdir(dir_name), key=lambda x:(len(x), x))
# print(video_list)
print('Merge Start')
with open(f'{dir_name}.ts', 'wb') as f1:
for t in video_list:
with open(os.path.join(dir_name, t), 'rb') as f2:
shutil.copyfileobj(f2, f1)
print('Merge complete')파일 이름이 1,2,3 ..., 10 이런 식으로 되어있을수도 있어서 길이부터 정렬하고 그 다음 숫자로 정렬했다.
마지막으로 합쳐진 파일을 제외하고 삭제한다.
import os
def delete_directory_and_file(dir_name):
print('Delete Start')
try:
for video in os.listdir(dir_name):
video_path = os.path.join(dir_name, video)
print(f'Delete {video_path}')
os.remove(video_path)
except:
print(f'Error - Cannot delete file {video}')
try:
os.rmdir(dir_name)
except:
print(f'Error - Cannot delete directory')
print('Delete Complete')
여기까지 오면 딱 하나의 동영상 파일이 만들어진다.
저장된 파일이 재생이 잘 되는지 확인하고, 원래 강의 시간과 파일의 시간이 같으면 제대로 저장된 것이므로 안심하고 강의를 보면된다.
import urllib.request
import re
import os
import shutil
def merge_videos(dir_name):
video_list = sorted(os.listdir(dir_name), key=lambda x:(len(x), x))
# print(video_list)
print('Merge Start')
with open(f'{dir_name}.ts', 'wb') as f1:
for t in video_list:
with open(os.path.join(dir_name, t), 'rb') as f2:
shutil.copyfileobj(f2, f1)
print('Merge complete')
def delete_directory_and_file(dir_name):
print('Delete Start')
try:
for video in os.listdir(dir_name):
video_path = os.path.join(dir_name, video)
print(f'Delete {video_path}')
os.remove(video_path)
except:
print(f'Error - Cannot delete file {video}')
try:
os.rmdir(dir_name)
except:
print(f'Error - Cannot delete directory')
print('Delete Complete')
def save_video_stream(video_url, extension, num_of_videos, save_directory_path=None):
'''
Download video streaming
video_url: In chrome or edge browser, developer tools - network tab - find xhr(media file)
extension: ts or mp4, etc. (I write ts)
num_of_videos: if you don't know number of videos, write big number
'''
# make directory
print('Make directory')
dir_name = save_directory_path
if dir_name:
if not os.path.exists(dir_name):
os.mkdir(dir_name)
else:
p = re.compile('.mp4$')
for s in video_url.split('/'):
m = p.search(s)
if m:
dir_name = s[:m.span()[0]]
if os.path.exists(dir_name):
pass
elif dir_name:
os.mkdir(dir_name)
else:
dir_name = video_url
os.mkdir(dir_name)
# download videos
print('Download videos')
try:
for num in range(num_of_videos + 1):
save_name = os.path.join(dir_name, f'{str(num).zfill(3)}.{extension}')
real_video_url = f'{video_url}{str(num)}.{extension}'
urllib.request.urlretrieve(real_video_url, save_name)
except:
print('No File Error or The End')
print("Download complete.")
# merge files
merge_videos(dir_name=dir_name)
# delete directory
delete_directory_and_file(dir_name=dir_name)
if __name__ == '__main__':
urls = [
'',
]
for url in urls:
save_video_stream(url,'ts', 1000)이렇게 하니 강의 영상들을 끊기지 않고 빠르게 넘길수도 있어서 만족한다.
여기서 더 나아가면 selenium을 사용해서 모든 강의의 링크를 알아오고, 한번에 저장할수 있을것이다.
하지만 그쯤이면 배보다 배꼽이 더 커지지 않을까?(이미 커진거 같긴한데...)
강의를 끊기지 않고 볼수 있음에 감사하며 이만 글을 마치도록 하겠다.
도움을 받은 글
https://uniconverter.wondershare.kr/online-video/how-to-download-streaming-video.html
'STUDY > Python' 카테고리의 다른 글
| [django] django.core.exceptions.SuspiciousOperation (0) | 2021.03.18 |
|---|---|
| 파이썬 객체지향(클래스, 인스턴스, 상속) (0) | 2021.01.05 |
| 파이썬 셋, 딕셔너리 (0) | 2021.01.03 |
| 댓글 작성하는 매크로 프로그램 (1) | 2020.10.23 |
| HTML5 동영상 다운로드 (1) | 2020.09.03 |